Linux上文件监控的踩坑分享
前言
在Linux主机安全产品HIDS中,文件监控是特别常见的需求,在实现方案上,Linux内核层提供了文件变动的通知机制fsnotify,然而,在高磁盘IO的主机上、不同版本的内核上以及海量监控目标中,将会面临哪些问题呢?业务性能与安全性如何做更好地取舍均衡?今天,我的小伙伴阿松给大家分享以下文件监控系统的建设历程。
文件监控的实现
Linux系统上,常见的文件监控一般有如下几种实现方案。
- 粗暴的周期性轮询,在内核不支持(比如伪文件系统),并且也没有特别好的方式的时候,轮询不失为一个办法,但是缺点如轮询字面表述的那样:
- 无论轮询周期多短,总可能会有事件的丢失;当然了,对于丢失事件不敏感的应用来说,这个也能接受;
- 为了减少事件的丢失,需要尽可能短的轮询周期,但是如果轮询周期太短,性能消耗就巨大,这是一个两难的选择;
- 不过,如果仅仅是感知个别文件的变动,还是可以采用短周期轮询的方式,但是如果是需要感知大量文件变动呢?
- 采用内核提供的fsnotify机制。在fsnotify的基础上,内核提供了给用户态使用的接口,这套接口从dnotify到inotify再到fanotify,也是经历了多次迭代;基于fsnotify机制,只需要watch 某个文件,然后等待内核上报文件变动的event即可。
在我们的业务场景中,需要对大量的文件进行监控,显然是不可能采用轮询了,经过多次测试验证,内核提供的inotify接口最能满足我们的需求;
inotify使用的方式大概如下,具体可参考:Linux man page inotify.7
- inotify_init,初始化inotify fd;
- inotify_add_watch,监控某个文件/目录;
- receive event,处理文件变动事件;
inotify的事件通知机制,以open事件为例子,inotify event的产生,反映在内核中是如下的函数调用链路:
open syscall -> fsnotify_open -> fsnotify -> send_to_group -> handle_event (inotify_handle_event)用户态的代码等待接收event,即可获取文件变动的数据。
inotify的踩坑优化
在生产环境中,一旦用户态功能需要和内核子系统进行大量的交互,那么由于生产环境的复杂性,难免会暴露出一些问题,而且生产环境业务的多样性使得开发者不得不尝试做更深入的思考;然而,即便是如此小心谨慎,还是踩到了一个坑;
第一次踩坑
背景大概是这样的,有一台机器上运行了文件监控服务A,在文件监控服务的一次变更中,突然发现某个业务服务器上发生了tcp timeout,时间线和文件监控服务的变更时间点完全一致,但这很难将文件监控的 功能跟TCP timeout异常这两个事情联系在一起。为了排查这些问题,我们请了内核组的同学协助排查,发现确实是能够复现tcp timeout这个问题;
通过review变更发现,本次变更仅仅是对监控的范围做了扩大,属于常规操作;因为监控的目标文件数量太多了,初步怀疑是高频次系统调用导致CPU内核态被打满,影响了正常网络业务的处理,导致tcp timeout。
但是随后的一系列实验,都否定了这个猜想,即系统调用的频率和tcp timeout无关。
tcp timeout问题分析
在一筹莫展之际,增加了inotify_add_watch系统调用的耗时统计,发现文件监控服务A在变更后,监控文件的整体流程(inotify_add_watch监控配置目录)的耗时异常高。这其实和认知不符合,正常的系统调用耗时应该极短;
那么只好在复现代码的流程上对每个inotify_add_watch的耗时做统计了,这一统计不要紧,发现有个目录就是很特别,一旦监控这个目录,那么某个CPU核内核态会被打满,耗时能到秒级;通过perf对测试代码进行火焰图分析,发现__fsnotify_update_child_dentry_flags耗时占了大头。
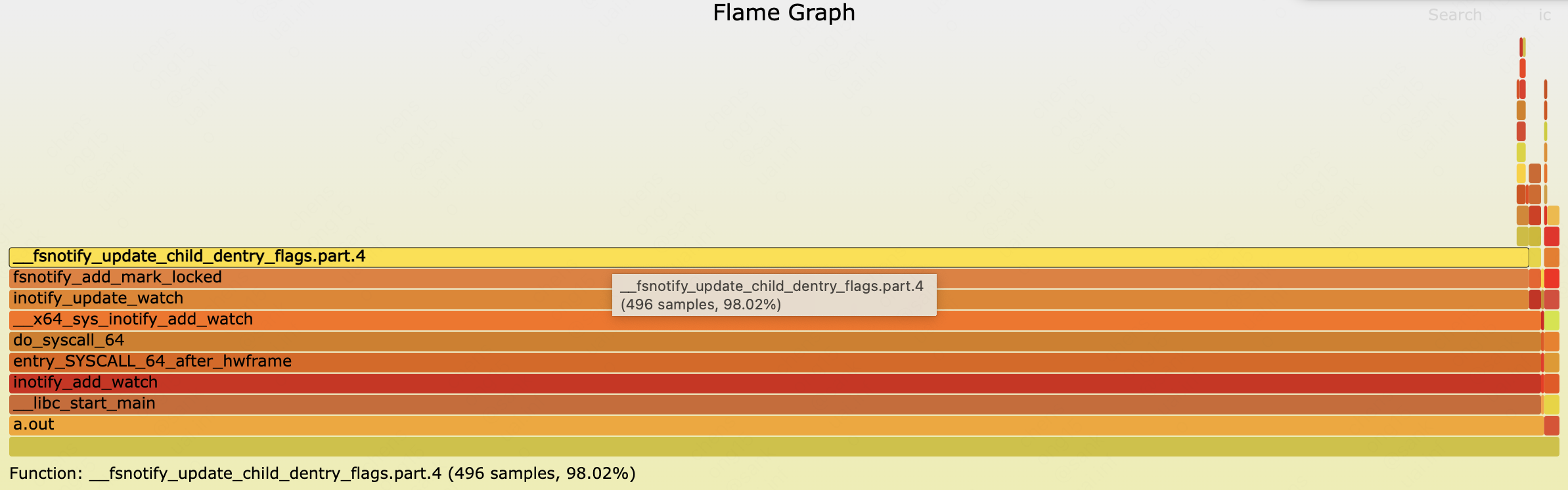
在这个函数中,可以看到似乎都是常规操作,Linux 3.10 fsnotify.c#L52,看起来让人不放心的是有一把inode的锁:spin_lock(&inode->i_lock);
spin_lock就是不停的询问资源有没有准备好的一把锁,使用spin_lock的的前提是:假设很快就能获得锁,且不会占用锁太久;
spin_lock不关闭中断,如果一个内核线程拿不到锁,它就会一直自旋等待锁可用,处于忙等状态,表现出来就是该线程所在的CPU的内核态几乎被打满。且由于该CPU不可被调度(服务器内核配置的PREEMPT_VOLUNTARY,实际就是不可抢占模式),那么该CPU会一直做无用功。
问题解决思路
所以基于perf分析和spin_lock的原理和使用场景,得出来如下结论:这个被监控的目录inode的spin_lock被某个进程长时间持有不释放,在文件监控服务A监控该目录,尝试获取spin_lock时一直自旋,导致CPU被打满,进而影响了正常的网络处理流程,导致tcp timeout。
查到这里,那么看起来如何解决tcp timeout的办法就比较清晰了:
- 找到长时间持有该目录inode的spin_lock的进程,kill掉;
- 文件监控服务A其实不太关注这个目录,直接移除对这个目录的监控就可以解决问题,实际上最终也是采取了这个方案;
文件监控的再次踩坑
上次的踩坑和欧,以为inode的锁占用问题得到了完全解决,但没想到后面又一次掉到坑里了。
后来复盘的时候做了回顾,之前inotify导致了个别服务器tcp timeout,且并没有其它的内核日志等证据来辅助证明,所以所有的证据都指向一个地方:这个目录被其它进程占用inode锁。这就为后面的再一次踩坑埋下伏笔。
case原委
某天,内核团队反馈,似乎有文件监控服务进程导致的soft lockup,可以从内核日志清晰看到。
当时收到反馈的时候整个人是懵的,受限于术业专攻,无法理解理解用户态的代码是如何导致内核态的soft lockup的;但现实是如此残酷,通过一系列的实验验证,确实能够复现soft lockup;
这里多亏了内核团队非常给力,内核团队通过分析soft lockup时的日志,发现问题点确实还是在__fsnotify_update_child_dentry_flags这个函数内部。
并且通过对内核日志的分析,可以精确定位到soft lockup时,实际卡住的地方在if (!child->d_inode)这个位置。这个判断条件是在一个循环的内部,循环内部遍历该inode所有的children,通过crash工具,也可以观察到当前这个目录对应inode下的children(然而是negative)很多;
void __fsnotify_update_child_dentry_flags(struct inode *inode)
{
struct dentry *alias;
int watched;
if (!S_ISDIR(inode->i_mode))
return;
/* determine if the children should tell inode about their events */
watched = fsnotify_inode_watches_children(inode);
spin_lock(&inode->i_lock);
/* run all of the dentries associated with this inode. Since this is a
* directory, there damn well better only be one item on this list */
hlist_for_each_entry(alias, &inode->i_dentry, d_u.d_alias) {
struct dentry *child;
/* run all of the children of the original inode and fix their
* d_flags to indicate parental interest (their parent is the
* original inode) */
spin_lock(&alias->d_lock);
list_for_each_entry(child, &alias->d_subdirs, d_child) {
if (!child->d_inode)
continue;
spin_lock_nested(&child->d_lock, DENTRY_D_LOCK_NESTED);
if (watched)
child->d_flags |= DCACHE_FSNOTIFY_PARENT_WATCHED;
else
child->d_flags &= ~DCACHE_FSNOTIFY_PARENT_WATCHED;
spin_unlock(&child->d_lock);
}
spin_unlock(&alias->d_lock);
}
spin_unlock(&inode->i_lock);
}通过分析crash文件,发现遍历的目录为/path/to/problem,但是通过ls查看,这个下面其实没几个子目录/文件。
如上所说,结合卡住的位置是在if (!child->d_inode),那么是不是可以推断,/path/to/problem这个目录下有大量的无效dentry呢?(参考:https://lwn.net/Articles/814535/);
dentry相关
当读写文件时,内核会为该文件对象建立一个dentry,并将其缓存起来,方便下一次读写时直接从内存中取出dentry提高效率。这些dentry cache可以让文件路径lookup工作大大加速,尤其是那些频繁访问的目录(如/tmp, /dev/null, /usr/bin/tetris)都在dentry cache里,可以节省大量filesystem I/O操作。
dentry属于slab cache,且dentry有三种状态:
- inuse,字段d_inode指向实际对象,且dentry的d_count大于0,不能被释放;
- unused,和inuse的区别在于这个dentry的d_count为0,也即是没有被引用,内存回收时可能会被释放;
- negative,d_inode不指向实际对象,这种dentry的产生主要有两种原因:
- 关联的inode已经被释放;
- 进程访问一些不存在的文件会产生这种dentry,这种dentry有利于加速不存在文件的检索(可以快速返回失败);
解开谜题
在上述的case中,结合已有的crash分析和业务情况可以发现,业务场景比较特殊,业务会在目录/path/to/problem中地创建随机文件名的文件然后删除,且频繁地重复这一动作;
这也就解释了为啥/path/to/problem这个目录下面有大量的negative dentry;显然在这种业务场景中,negative dentry加速访问的作用不明显,但遗憾的是内核并未提供相关的接口进行细粒度的删除。
在此进一步说明,如下的红框中的代码是真正导致耗时居多的地方。

复现soft lockup
有了以上的结论,就可以尝试复现soft lockup这一现象,看看是不是和我们的推断(inode下negative dentry太多,watch时导致soft lockup)完全契合。
复现soft lockup准备工作:
-
首先清空slab cache,
echo 2 > /proc/sys/vm/drop_caches; -
为了缩短复现时间,调低soft lockup的阈值,比如
echo 1 > /proc/sys/kernel/watchdog_thresh; -
准备测试代码inotify_watch,就做一件事情,inotify_add_watch目录/tmp/test;
- 代码可以参考Linux man pages inotify;
-
使用time ./inotify_watch测试内核态的耗费时间,实际测试可以看到,耗时基本为0;
-
在/tmp/test这个目录中,随机生成文件名然后删除,高频次做这一动作;
#! /bin/bash num=0 while true; do ((num++)) rm -f /tmp/test/$num.tmp > /dev/null done -
dentry cache的大小可以通过slabtop –once观测,上述脚本运行时定时观测dentry cache的增大现象;
-
等到dentry cache增大到一定量,比如到5GB;
-
使用time ./inotify_watch测试内核态的耗费时间,可以发现内核态耗时可能在3S左右;
-
dmesg -T也能查看到对应的soft lockup日志,和之前的火焰图是一致的,call Trace如下:
call Trace:inotify_add_watch -> entry_SYSCALL_64_after_hwframe -> do_syscall_64 -> x64_sys_inotify_add_watch -> inotify_update_watch -> fsnotify_add_mark_locked -> fsnotify_update_child_dentry_flags
再次梳理问题链路
基于以上的分析流程,再次梳理下soft lockup问题产生的链路,分析下是否还会有其它影响:
- 目录
/path/to/problem下的dentry cache特别多,比如占据内存10GB,可能其中大部分都是negative dentry; inotify_add_watch对/path/to/problem这个目录进行了watch;- 用户态代码调用
inotify_add_watch监控/path/to/problem这个目录时,调用链路中会调用__fsnotify_update_child_dentry_flags这个函数; __fsnotify_update_child_dentry_flags函数会对这个目录对应inode下的所有dentry(包括negative dentry)进行遍历,耗时太多导致在该CPU上产生了soft lockup;- 另外,因为目录
/path/to/problem的inode的spin_lock被该内核线程占用太久,如果此时有其他进程需要获取该目录对应inode的spin_lock时,也会在其它CPU上产生soft lockup; - 所以,综上,如果
/path/to/problem目录对应inode下的dentry巨多,soft lockup会有两个触发路径:- Inotify_add_watch导致,由于内核线程A持有目录
/path/to/problem inode的i_lock,占据CPU 1太久导致soft lockup; - 这时候内核线程B也尝试获取目录
/path/to/problem的i_lock,因为长时间获取不到,spin_lock自旋导致CPU 2产生soft lockup;
- Inotify_add_watch导致,由于内核线程A持有目录
问题解决方式
到此,问题已经描述清晰了,那么要如何解决呢?
-
社区也提出了一些解决方式,但是并没有合并到主线代码:
https://lore.kernel.org/lkml/20220209231406.187668-5-stephen.s.brennan@oracle.com/T/#m039bc61f4ea656bc268b7f565973d9924af15652 -
如上的复现步骤中,可以看到,通过清空
dentry cache(echo 2 > /proc/sys/vm/drop_caches)的方式来解决,但是由于dentry和inode cache的特殊作用,该操作可能会带来性能下降,作为应急方案比较合适; -
文件监控服务中,对于要监控的目标目录有清晰的认知,要结合业务情况做监控目标的取舍。比如某些业务在某个目录高频次创建删除随机文件名文件,或者高频次尝试访问不存在的文件,那么这时候这个目录需要被加入黑名单;
总结
这两个问题,是我们遇到的比较复杂的问题,甚至是Linux Kernel的文件系统缺陷,在这里分享给大家。如果大家有更好的解决方案,也欢迎留言交流。
文件监控是特别常见、特别普通的功能,然而,在生产环境中运行时,会因为环境、业务、需求等不同,遇到各种各样的问题,而这些问题的发生,将严重拉长HIDS类产品的覆盖周期。面对疑难杂症,务必要有一颗打破砂锅问到底的心,才能定位出问题根因,给出更加高效的解决方案,保证安全产品的快速覆盖。
武林秘籍
追根究底,追求卓越,永远都是工程师最珍贵的品质。小弟,既然读到这里了,想必你也是全身散发着这种品质,我看你计算机内功极厚,简直是百年难得一遇的编程奇才,我这里有个招聘,你要不要来试试。

职位:反爬蓝军对抗专家
职位隶属美团-基础研发平台-信息安全部,办公地点在北京望京、上海杨浦,两地任选。要求候选人需要在相关领域具备3年以上工作经验。
职位详情:https://mp.weixin.qq.com/s/IkWNRYUOWuh0woL0_Uzg2w
 CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:Linux上文件监控的踩坑分享
CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:Linux上文件监控的踩坑分享
老哥 请问 面对大文件的 copy 的时候, 单独的 inotify 只是 通知文件夹,被创建,
如果确认大文件的copy 是否结束呢,请问 老哥 有相关经验吗?
Linux trace跟踪吧,比如TracePoint、Kprobe、eBPF之类的,挂到关闭函数上,再判断文件名是否符合需求。 我也没别的好 思路了。