译者注
原文链接:Live-patching security vulnerabilities inside the Linux kernel with eBPF Linux Security Module
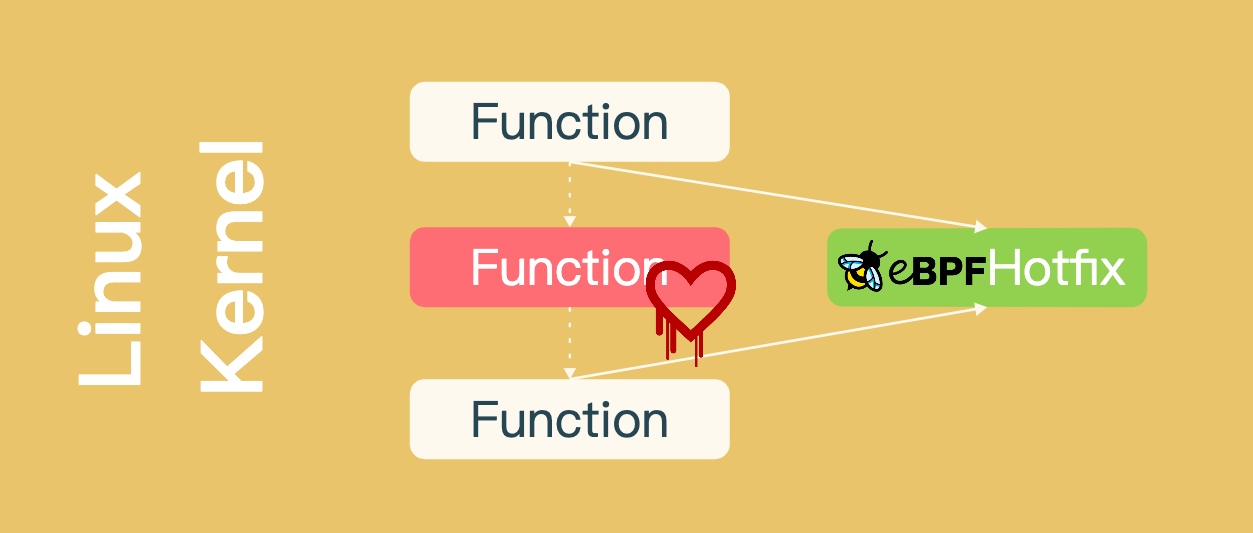
前段时间,我们讨论了Tetragon产品实时阻断能力的实现原理,那你知道它为什么没选择eBPF LSM吗?
系统内核版本要求是最大限制,eBPF LSM需要5.7以后版本。但对于安全产品,阻断一个函数的调用,远比杀死一个进程影响要小。bpf_send_signal颗粒度是进程,eBPF LSM的颗粒度是函数,更精确。除此之外,控制范围也不一样,可以对函数调用堆栈做调整,达到替换执行的目标函数。业务场景就是内核漏洞的热更新了。
而本文就是一个简单的eBPF LSM实现思路,核心内容是确定精准HOOK点的思路。怎么找HOOK点?HOOK点挂载后,对性能影响是什么?如何做权衡?接下来,我们一起了解一下。
前言
Linux Security Modules(LSM)是一个钩子的基于框架,用于在Linux内核中实现安全策略和强制访问控制。 直到现在,能够实现实施安全策略目标的方式只有两种选择,配置现有的LSM模块(如AppArmor、SELinux),或编写自定义内核模块。
Linux Kernel 5.7引入了第三种方式:LSM扩展伯克利包过滤器(eBPF)(简称BPF LSM)。 LSM BPF允许开发人员编写自定义策略,而无需配置或加载内核模块。 LSM BPF程序在加载时被验证,然后在调用路径中,到达LSM钩子时被执行。
实践出真知
Namespaces 命名空间
现代操作系统提供了允许对内核资源进行partitioning的工具。 例如FreeBSD有jails,Solaris有zones。 Linux是不同的—它提供了一组看似独立的工具,每个进程都允许隔离特定的资源。 他就是Namespaces,经过多年来不停迭代,孕育了Docker、lxc、firejail应用。 大部分Namespaces是没有争议的,如UTS命名空间,它允许主机系统隐藏主机名和时间。其他的则比较复杂但简单明了————众所周知,NET和NS(mount)命名空间很难让人理解。最后,还有一个非常特殊、非常有趣的USER Namespaces。
USER Namespaces很特别,因为它允许所有者作为root操作。其工作原理超出了本文的范围,但是,可以说它是让Docker等工具不作为真正的root操作,或者说是rootless容器。
由于其特性,允许未授权用户访问USER Namespaces总是会带来很大的安全风险。其中最大的风险是提权。
提权原理
提权是操作系统的常见攻击面。 user获得权限的一种方法是通过unshare syscall将其命名空间映射到root空间,并指定CLONE_NEWUSER标志。 这会告诉unshare创建一个具有完全权限的新用户命名空间,并将新用户和Group ID映射到以前的命名空间。 即使用unshare(1)程序将root映射到原始命名空间:
$ id
uid=1000(fred) gid=1000(fred) groups=1000(fred) …
$ unshare -rU
# id
uid=0(root) gid=0(root) groups=0(root),65534(nogroup)
# cat /proc/self/uid_map
0 1000 1多数情况下,使用unshare是没有风险的,都是以较低的权限运行。 但是,已经被用于提权了,比如CVE-2022-0492,那么本文就重点以这个场景为例。
Syscalls clone和clone3也很值得研究,都有CLONE_NEWUSER的功能。但在这篇文章中,我们将重点关注unshare。
Debian用add sysctl to disallow unprivileged CLONE_NEWUSER by default补丁解决了这个问题,但它没有被合并到源码mainline主线中。另一个类似的补丁"sysctl: allow CLONE_NEWUSER to be disabled"尝试合并到mainline,但被拒绝了。理由是在某些特定应用中无法切换到该特性。 在Controlling access to user namespaces一文中,作者写道:
… 目前的补丁似乎没有一条通往mainline主线的捷径。
如你所示,补丁最终没有包含到vanilla内核中。
我们的解决方案LSM BPF
基于上面一些经验,可以看到限制USER Namespaces的代码似乎行不通,我们决定使用LSM BPF来规避这些问题。并且不需要修改内核,还可以自定义检测防御的规则。
寻找合适的候选钩子
首先,让我们跟踪我们的目标系统调用。 我们可以在include/linux/syscalls.h文件中找到原型。
/* kernel/fork.c */很清晰的看到,在kernel/fork.c文件中,注释部分中留下了下一个位置的线索。 在ksys_unshare()那里调用。深入研究该函数,发现了一个对unshare_userns()的调用。这让我看到了希望。
现在,我们已经确定了syscall实现,但是接下来的问题是用哪些钩子?怎么选择合适的钩子?
从man-pages中了解到unshare用于改变task,那么,我们重点关注include/linux/lsm_hooks.h中的关于task的钩子。 在函数unshare_userns()中,可以找到对prepare_creds()的调用。对于cred_prepare的HOOK来说看上去不看。 为了验证对prepare_creds()的理解是否正确,接下来继续分析security_prepare_creds()的调用,可以确认,其最终会调用这个HOOK:
…
rc = call_int_hook(cred_prepare, 0, new, old, gfp);
…暂不过多讨论这个问题,现在能确认的是这个HOOK比较合适,因为prepare_creds()正好在unshare_userns()中的create_user_ns()之前被调用,而unshare_userns()是我们试图阻止的操作。
LSM BPF解决方案
我们将使用eBPF编译一次到处运行(CO-RE)的方法对代码进行编译。 在不同版本内核的IDC中,会特别适用。(不过,国内外大部分五至十年的互联网公司,都有着大量低于5.0的内核版本)。本文的演示,将只对x86_64 CPU架构系统验证。ARM64的LSM BPF仍在开发中。你可以订阅BPF邮件列表来了解最新进展。
此解决方案在Kernel Version >=5.15上进行了测试,配置如下:
BPF_EVENTS
BPF_JIT
BPF_JIT_ALWAYS_ON
BPF_LSM
BPF_SYSCALL
BPF_UNPRIV_DEFAULT_OFF
DEBUG_INFO_BTF
DEBUG_INFO_DWARF_TOOLCHAIN_DEFAULT
DYNAMIC_FTRACE
FUNCTION_TRACER
HAVE_DYNAMIC_FTRACE如果CONFIG_LSM列表中不包含bpf,则需要你自己重新编译,并开启lsm=bpf选项.
内核空间代码
开始看内核空间代码:deny_unshare.bpf.c:
#include <linux/bpf.h>
#include <linux/capability.h>
#include <linux/errno.h>
#include <linux/sched.h>
#include <linux/types.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
#define X86_64_UNSHARE_SYSCALL 272
#define UNSHARE_SYSCALL X86_64_UNSHARE_SYSCALLCO-RE
接下来,我们以下列方式为CO-RE重新定位建立必要的结构:
deny_unshare.bpf.c:
…
typedef unsigned int gfp_t;
struct pt_regs {
long unsigned int di;
long unsigned int orig_ax;
} __attribute__((preserve_access_index));
typedef struct kernel_cap_struct {
__u32 cap[_LINUX_CAPABILITY_U32S_3];
} __attribute__((preserve_access_index)) kernel_cap_t;
struct cred {
kernel_cap_t cap_effective;
} __attribute__((preserve_access_index));
struct task_struct {
unsigned int flags;
const struct cred *cred;
} __attribute__((preserve_access_index));
char LICENSE[] SEC("license") = "GPL";
…我们不需要完全充实 struct 的细节,只需提供程序正常运行所需信息的绝对下限。CO-RE 将执行为内核执行调整所需的任何操作。这样就可以很轻松地编写 LSM BPF 程序!
// deny_unshare.bpf.c:
SEC("lsm/cred_prepare")
int BPF_PROG(handle_cred_prepare, struct cred *new, const struct cred *old,
gfp_t gfp, int ret)
{
struct pt_regs *regs;
struct task_struct *task;
kernel_cap_t caps;
int syscall;
unsigned long flags;
// If previous hooks already denied, go ahead and deny this one
if (ret) {
return ret;
}
task = bpf_get_current_task_btf();
regs = (struct pt_regs *) bpf_task_pt_regs(task);
// In x86_64 orig_ax has the syscall interrupt stored here
syscall = regs->orig_ax;
caps = task->cred->cap_effective;
// Only process UNSHARE syscall, ignore all others
if (syscall != UNSHARE_SYSCALL) {
return 0;
}
// PT_REGS_PARM1_CORE pulls the first parameter passed into the unshare syscall
flags = PT_REGS_PARM1_CORE(regs);
// Ignore any unshare that does not have CLONE_NEWUSER
if (!(flags & CLONE_NEWUSER)) {
return 0;
}
// Allow tasks with CAP_SYS_ADMIN to unshare (already root)
if (caps.cap[CAP_TO_INDEX(CAP_SYS_ADMIN)] & CAP_TO_MASK(CAP_SYS_ADMIN)) {
return 0;
}
return -EPERM;
}第一步是创建程序,第二步是加载程序并附加到我们所需的钩子上。
用户空间
加载程序并将其附加到目标的钩子上是用户空间的功能。有几种方法可以做到这一点:
- Cilium ebpf项目
- Rust bindings
- ebpf.io项目
landscape展示的其他类库
这里,我们将使用原生libbpf。
#include <bpf/libbpf.h>
#include <unistd.h>
#include "deny_unshare.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char *argv[])
{
struct deny_unshare_bpf *skel;
int err;
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
libbpf_set_print(libbpf_print_fn);
// Loads and verifies the BPF program
skel = deny_unshare_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "failed to load and verify BPF skeleton\n");
goto cleanup;
}
// Attaches the loaded BPF program to the LSM hook
err = deny_unshare_bpf__attach(skel);
if (err) {
fprintf(stderr, "failed to attach BPF skeleton\n");
goto cleanup;
}
printf("LSM loaded! ctrl+c to exit.\n");
// The BPF link is not pinned, therefore exiting will remove program
for (;;) {
fprintf(stderr, ".");
sleep(1);
}
cleanup:
deny_unshare_bpf__destroy(skel);
return err;
}Makefile
最后,进行编译,这里使用Makefile
CLANG ?= clang-13
LLVM_STRIP ?= llvm-strip-13
ARCH := x86
INCLUDES := -I/usr/include -I/usr/include/x86_64-linux-gnu
LIBS_DIR := -L/usr/lib/lib64 -L/usr/lib/x86_64-linux-gnu
LIBS := -lbpf -lelf
.PHONY: all clean run
all: deny_unshare.skel.h deny_unshare.bpf.o deny_unshare
run: all
sudo ./deny_unshare
clean:
rm -f *.o
rm -f deny_unshare.skel.h
#
# BPF is kernel code. We need to pass -D__KERNEL__ to refer to fields present
# in the kernel version of pt_regs struct. uAPI version of pt_regs (from ptrace)
# has different field naming.
# See: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=fd56e0058412fb542db0e9556f425747cf3f8366
#
deny_unshare.bpf.o: deny_unshare.bpf.c
$(CLANG) -g -O2 -Wall -target bpf -D__KERNEL__ -D__TARGET_ARCH_$(ARCH) $(INCLUDES) -c $< -o $@
$(LLVM_STRIP) -g $@ # Removes debug information
deny_unshare.skel.h: deny_unshare.bpf.o
sudo bpftool gen skeleton $< > $@
deny_unshare: deny_unshare.c deny_unshare.skel.h
$(CC) -g -Wall -c $< -o $@.o
$(CC) -g -o $@ $(LIBS_DIR) $@.o $(LIBS)
.DELETE_ON_ERROR:结果
打开一个新终端,运行命令
$ make run
…
LSM loaded! ctrl+c to exit.在另一个终端里,可以看到成功的被阻止了。
$ unshare -rU
unshare: unshare failed: Cannot allocate memory
$ id
uid=1000(fred) gid=1000(fred) groups=1000(fred) …这个策略还有一项始终允许特权通过的功能。
$ sudo unshare -rU
# id
uid=0(root) gid=0(root) groups=0(root)在无特权场景中,系统调用会提前中止。 有特权情况下的性能影响是什么?
性能对比
我们将使用一行unshare命令来映射用户命名空间,并在中执行一个命令来进行测量:
$ unshare -frU --kill-child -- bash -c "exit 0"使用系统调用unshare enter/exit的CPU周期间隔,我们将以root用户身份测量以下内容:
- 命令在没有策略的情况下运行
- 与策略一起运行的命令
我们将使用ftrace记录测量结果:
$ sudo su
# cd /sys/kernel/debug/tracing
# echo 1 > events/syscalls/sys_enter_unshare/enable ; echo 1 > events/syscalls/sys_exit_unshare/enable此时,我们将专门为unshare启用对系统调用enter/exit的跟踪。 现在,我们设置enter/exit调用的time-resolution来计算CPU周期:
# echo 'x86-tsc' > trace_clock 接下来,我们开始评测
# unshare -frU --kill-child -- bash -c "exit 0" &
[1] 92014在新终端里运行策略,执行下一个syscall
# unshare -frU --kill-child -- bash -c "exit 0" &
[2] 92019现在,我们收集到两种CALLS结果进行对比
# cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 4/4 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / _-=> migrate-disable
# |||| / delay
# TASK-PID CPU# ||||| TIMESTAMP FUNCTION
# | | | ||||| | |
unshare-92014 [002] ..... 762950852559027: sys_unshare(unshare_flags: 10000000)
unshare-92014 [002] ..... 762950852622321: sys_unshare -> 0x0
unshare-92019 [007] ..... 762975980681895: sys_unshare(unshare_flags: 10000000)
unshare-92019 [007] ..... 762975980752033: sys_unshare -> 0x0分别是:
- unshare-92014 used 63294 cycles.
- unshare-92019 used 70138 cycles.
两次测量之间有6,844(~10%)个周期损失。不错嘛!
这些数字是针对单个系统调用的,代码调用的频率越高,这些数字就越多。 Unshare通常在任务创建时调用,在程序的正常执行期间不会重复调用。 对于你的场景,需要仔细考虑评估。
结尾
我们了解了LSM BPF是什么,如何使用unshare将user映射到root,以及如何通过在eBPF中实现程序来解决真实场景的问题。跟踪准确的钩子不是一件容易的事,需要有丰富的编码经验,以及丰富的内核知识。 这些策略代码是用C语言编写的,所以我们可以因地制宜,不同的问题做不同的策略,代码轻微调整,就可以快速扩展,增加其他钩子点等。最后,我们对比了这个LSM程序的性能影响,性能与安全的权衡,是你需要考虑的问题。
Cannot allocate memory(无法分配内存)不是拒绝权限的最准确的描述。 我们提出了一个补丁,用于将错误代码从cred_prepare挂钩传到调用堆栈。
最后,我们的结论就是eBPF LSM钩子非常适合实时修复Linux内核漏洞,你要来试试吗?
 CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:使用eBPF LSM热修复Linux内核漏洞
CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:使用eBPF LSM热修复Linux内核漏洞
缺少了BPF_PROG部分代码,看起来有点懵。
补齐了。