译者注:
原文为https://www.parca.dev/的Javier Honduvilla Coto,文章地址DWARF-based Stack Walking Using eBPF,副标题Deep dive into the new DWARF-based stack unwinder using eBPF,即深度解析使用eBPF基于DWARF的栈展开。 文章为机翻,以及人工矫正。译者水平有限,有疑问请看原文。
parca项目介绍
parca是一款基于eBPF技术实现的CPU、内存观测产品。可以持续分析 CPU 和内存使用情况产品,细化到行号和整个时间。 节省基础架构成本、提高性能并提高可靠性。 GitHub地址:https://github.com/parca-dev/parca
原文:
采样CPU分析器周期性地获取目标进程的堆栈,比如用C、C++、Rust等语言编写的进程,可能比大家想象的要复杂一些。最普遍的问题是因为缺少frame pointer帧指针。
我们已经开发了一个改进的堆栈遍历器 :Parca continuous profiling Agent,即使在省略了帧指针的情况下也能工作。
x86_64中的堆栈
x86_64架构除了描述它的指令集和其他一些重要特征外,还定义了数据在其应用二进制接口或简称ABI中应如何布局的规则。该规范显示了该架构下的堆栈应该如何设置。
当这段代码被执行时,不同的call指令将把返回地址压入堆栈中。一旦函数返回,CPU将读取返回地址并跳转到该地址,继续执行该函数的调用点。
由于没有额外的信息,不可能可靠地生成堆栈跟踪。可能有其他的值,比如函数的本地数据,被存储在堆栈中,可能看起来像函数地址。这就是帧指针要解决的问题。
Can I have a (frame) pointer?
如下伪代码为例,假设没有编译器优化
int top(void) {
for(;;) { }
}
int c1(void) {
top();
}
int b1(void) {
c1();
}
int a1(void) {
b1();
}
int main(void) {
a1();
}使用这方法来遍历堆栈,我们需要保留指向上一帧的指针。 在x86体系结构中,这通常在帧指针$rbp中。 由于函数可能调用其他函数,因此必须在函数进入时存储该寄存器,并在函数退出时恢复该寄存器。
这是通过所谓的function prologue函数序言来实现的,在函数入口处,它可能看起来像这样
push $rbp # saves the stack frame pointer
mov $rbp, $rsp # sets the current stack pointer to the frame pointerfunction epilogue函数序言在函数返回处
pop $rbp # restores the function's frame pointer
ret # pops the saved return address and jumps to it如果我们用帧指针编译并运行上面的C代码,堆栈将具有遍历堆栈所需的所有信息。 有效地调用不同的函数会创建一个需要遍历的链表。
反汇编使用帧指针编译的代码
# compiled with `gcc sample.c -o sample_with_frame_pointers -fno-omit-frame-pointer`
$ objdump -d ./sample_with_frame_pointers
0000000000401106 <top>:
401106: 55 push %rbp
401107: 48 89 e5 mov %rsp,%rbp
40110a: eb fe jmp 40110a <top+0x4>
000000000040110c <c1>:
40110c: 55 push %rbp
40110d: 48 89 e5 mov %rsp,%rbp
401110: e8 f1 ff ff ff call 401106 <top>
401115: 90 nop
401116: 5d pop %rbp
401117: c3 ret
0000000000401118 <b1>:
401118: 55 push %rbp
401119: 48 89 e5 mov %rsp,%rbp
40111c: e8 eb ff ff ff call 40110c <c1>
401121: 90 nop
401122: 5d pop %rbp
401123: c3 ret
0000000000401124 <a1>:
401124: 55 push %rbp
401125: 48 89 e5 mov %rsp,%rbp
401128: e8 eb ff ff ff call 401118 <b1>
40112d: 90 nop
40112e: 5d pop %rbp
40112f: c3 ret
0000000000401130 <main>:
401130: 55 push %rbp
401131: 48 89 e5 mov %rsp,%rbp
401134: e8 eb ff ff ff call 401124 <a1>
401139: b8 00 00 00 00 mov $0x0,%eax
40113e: 5d pop %rbp
40113f: c3 ret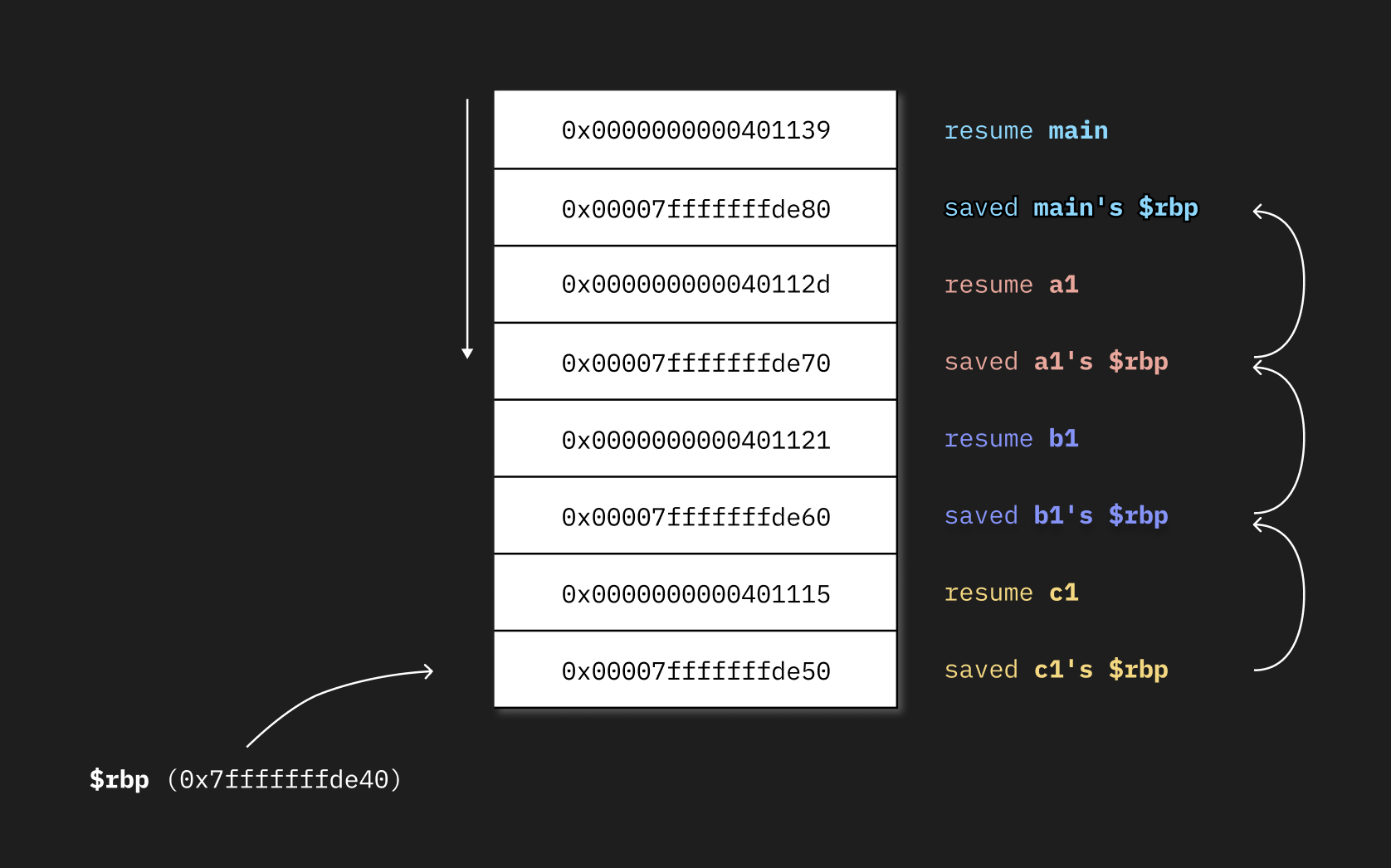 上面的例子代码中的native stack的内容是在顶部函数运行时用帧指针编译的
上面的例子代码中的native stack的内容是在顶部函数运行时用帧指针编译的
要遍历堆栈,我们必须遵循上面生成的链表,读取每个保存的$rbp之前压入的值,这将使我们的堆栈帧,直到$rbp为零,意味着已经到达了堆栈的末尾。
这很好,因为它允许我们以很低的成本计算出堆栈跟踪。 对于编译器实现者来说,添加它也相对容易,而且一般来说,只需要相当少量的周边基础设施就可以使它工作。
尽管有这些优点,但我们所依赖的许多代码并不是用帧指针编译的。 我们中的许多人依赖于我们的Linux发行版应用程序和库,其中绝大多数选择省略帧指针。 即使你使用框架指标编译程序,动态或静态链接你的发行版本所提供的任何库,也可能会让你无法仅使用帧指针来正确展开堆栈。
我们不会深入探讨在某些环境中禁用帧指针的原因以及与之相关的细微差别,但我们认为必须逐个应用地对它们的开销进行基准测试。 禁用帧指针带来的成本也应该考虑在内。
反汇编不使用帧指针编译的代码
# compiled with `gcc sample.c -o sample_without_frame_pointers -fomit-frame-pointer`
$ objdump -d ./sample_without_frame_pointers
[...]
0000000000401106 <top>:
401106: eb fe jmp 401106 <top>
0000000000401108 <c1>:
401108: e8 f9 ff ff ff call 401106 <top>
40110d: 90 nop
40110e: c3 ret
000000000040110f <b1>:
40110f: e8 f4 ff ff ff call 401108 <c1>
401114: 90 nop
401115: c3 ret
0000000000401116 <a1>:
401116: e8 f4 ff ff ff call 40110f <b1>
40111b: 90 nop
40111c: c3 ret
000000000040111d <main>:
40111d: e8 f4 ff ff ff call 401116 <a1>
401122: b8 00 00 00 00 mov $0x0,%eax
401127: c3 ret
[...]二者差异
top:
- push %rbp
- mov %rsp,%rbp
jmp 40110a <top+0x4>
c1:
- push %rbp
- mov %rsp,%rbp
call 401106 <top>
nop
- pop %rbp
ret
b1:
- push %rbp
- mov %rsp,%rbp
call 40110c <c1>
nop
- pop %rbp
ret
a1:
- push %rbp
- mov %rsp,%rbp
call 401118 <b1>
nop
- pop %rbp
ret
main:
- push %rbp
- mov %rsp,%rbp
call 401124 <a1>
mov $0x0,%eax
- pop %rbp
ret假设我们在分析c1的执行过程,堆栈可能如下所示:
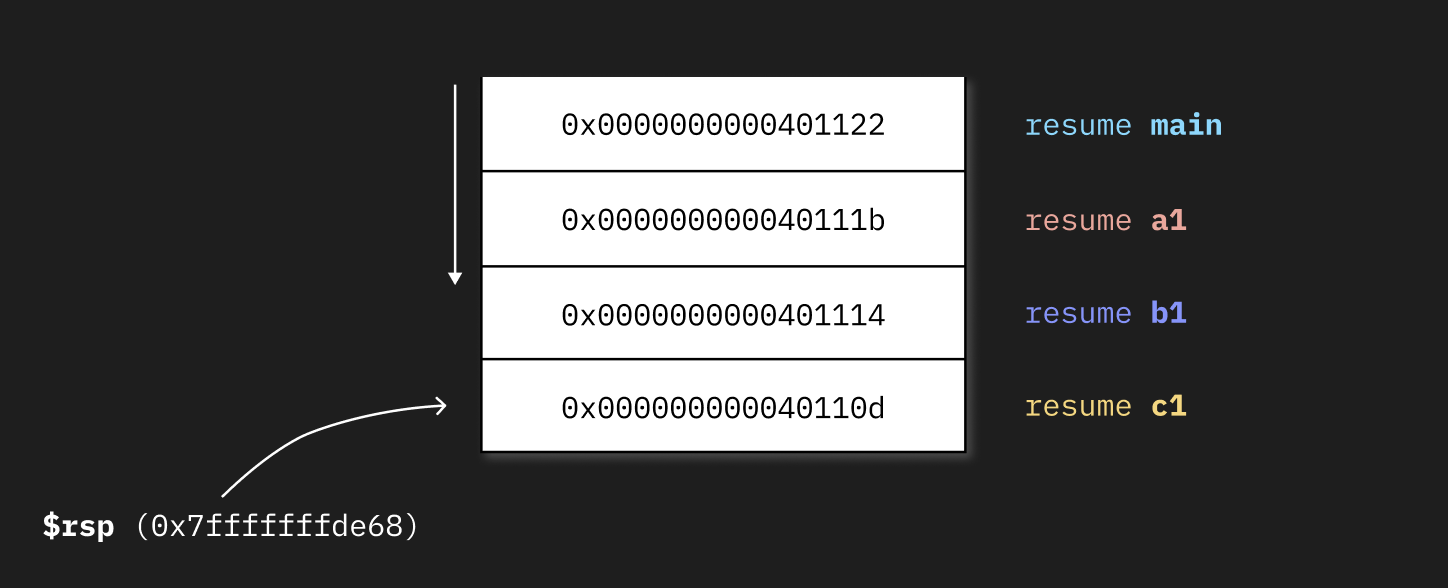 top运行时上述代码的native stack的内容
top运行时上述代码的native stack的内容
我们需要一些其他信息或硬件支持,以便能够可靠地展开堆栈。
硬件方法
我们可以使用一些硬件设施来展开堆栈,例如Intel的Last Branch Record (LBR).LBR产生起始地址和目的地址对FROM_IP和TO_IP。我们可以使用它们来建立堆栈跟踪。 他的缺点就是他能记录的深度有限。
虽然 LBR 用途广泛且功能强大,但我们决定不将其用于 CPU 分析,因为并非每个虚拟化环境都提供此功能,而且它是英特尔特有的。这些缺点延伸到其他感兴趣的供应商特定的处理器特征,例如 Intel Processor Trace (PT)
一场特殊的邂逅
你可能会想,我怎么可能编译没有帧指针的C++应用程序,并且异常仍然工作得很好? 那么Rust呢?在Rust中,默认情况下帧指针是禁用的,但是调用panic() 会显示完整且正确的堆栈跟踪。
为了使C++异常无论二进制代码是如何编译的都能工作,以及添加一些其他必要的工具来使它们发挥作用,编译器可以发出一些元数据来指示如何展开堆栈。 该信息提供程序计数器到关于如何恢复所有寄存器的指令的映射。
更多详情参见 DWARF debugging information format 和 x86_64 ABI两篇文章。
DWARF’s Call Frame Information (CFI)
CFI的主要目标是提供如何在我们代码执行的任何部分恢复前一帧的每个寄存器的答案。直接存储一个包含每个程序计数器和所有寄存器及其位置(例如它们是否已被压入堆栈)的表,将生成巨大的展开表。
因此,此格式尽量紧凑,仅包含所需的信息。 它使用各种技术来达到此效果,例如
- 使用 LEB128实现数字的可变长度压缩
- 使用状态机进行数据压缩。 这一点很重要,因为它允许以增加复杂性为代价来实现数据的非常简洁的表示
回溯表以CFI格式编码,采用我们需要计算的操作码的形式。 它有两个主要的层。第一层是在VM中编码的状态机。 这有助于压缩性能良好的重复模式,并允许更紧凑地表示某些数据,因为在某些情况下,有一个专门的操作码占用1、2或4个字节,而不是一直使用4个字节。 未压入堆栈的寄存器可能不会出现在表中。
我称之为第二层的是一个特殊的操作码,它包含另一组操作码,包含我们需要计算的任意表达式。 这两个层次之间的主要区别是,对于第一层次,我们只需要一个堆栈来记忆和恢复寄存器(分别为DW_CFA_remember_state和DW_CFA_restore_state),对于第二层,我们需要计算任意图灵完整表达式。 因此,我们需要一个成熟的VM来计算任何表达式。
在BPF中实现VM并不太实际,因此我们决定采用一种实用的方法,首先对2个表达式进行硬编码,这2个表达式在我们评估的大多数二进制文件中出现的次数超过50%。 我们有一些关于如何进一步改进表达式支持的想法,但是这篇博客文章已经太长了。
使用DWARF CFI遍历堆栈
要使用此方法遍历给定程序计数器(PC)的堆栈,我们需要找到其相应的展开信息。 但是,我们所说的展开信息到底是什么意思呢?
我们需要恢复:
- 已保存的返回地址
- 前一帧的栈指针(
$rsp)和帧指针($rbp)寄存器的值,用于恢复前一帧的栈指针
前一帧的堆栈指针的值,就在我们当前函数被调用之前,在 DWARF 的 CFI 术语中,称为规范帧地址或 CFA。 正如我们之前看到的,在 x86_64 中,保存的返回地址总是在 CFA 之前 8 个字节(一个字)。
展开算法看起来像这样
- 读取初始寄存器
- 指令指针
$rip。 需要在展开表中查找行。 - 堆栈指针
$rsp和帧指针$rbp,用于计算前一帧的堆栈指针值 (CFA)。 我们可以在 CFA 的偏移量处找到压入堆栈的返回地址和其他寄存器。
- 指令指针
- While循环
unwind_frame_count <= MAX_STACK_DEPTH:- 找到
i满足的 PC 的展开表行$unwind_table[i].PC <= $target_PC <= $unwind_table[i+1].PC。- 如果没有记录并且
$rbp为零,我们就到达了堆栈的底部。
- 如果没有记录并且
- 将指令指针添加到堆栈。
- 计算前一帧的栈指针。 这可以基于当前帧的
$rsp或$rbp,如果它不是表达式或直接注册。 - 用前一帧的计算值更新寄存器。
- 继续下一帧。 转到2。
- 找到
Note: 为简单起见,我们省略了我们的展开器实现的一些重要细节.
为此,我们需要读取回溯操作码,对它们求值,然后生成表。 这个过程可能会非常昂贵,但它是由C++中的异常处理基础结构完成的。 因为异常应该是,呃,异常,所以这些代码路径不应该经常使用,开销也不会太高。
对于调试器(如GDB)也是如此,在调试器中,用户可能希望了解各处的堆栈跟踪,以了解他们在执行中的位置。 这些用例有时被归类为离线展开。
分析器有点不同,因为它们通常每秒对堆栈进行数十次或数百次采样。必须读取、解析和评估展开信息的开销可能非常高。虽然堆栈展开器可能会做一些缓存,但整个过程仍然非常昂贵。
在我们的案例中,一个关键的观察结果是,我们不需要恢复每个寄存器,我们只需要这2个寄存器和保存的返回地址。 这种洞察力使我们能够生成一种更适合在线展开用例的表示。
可能的实现
我们开发的分析器并不是第一个使用这种技术的分析器。 Perf是一个古老的Linux分析器,它支持基于DWARF的堆栈展开已经有一段时间了。 通过利用Linux 3.4中的perf_event_open系统调用中引入的PERF_SAMPLE_REGS_USER和PERF_SAMPLE_STACK_USER,它可以接收所分析进程的寄存器以及每个样本的堆栈副本。
虽然这种方法已经被证明是可行的,并且我们对实现我们的分析器进行了类似的评估,但它有一些我们希望避免的缺点:
- 性能:内核将为每个样本复制用户堆栈。 它会复制当前正在使用的用户堆栈,但这可能是相当多的数据。 假设非常保守的情况是:
每栈1 K * 每秒100个样本 * CPU运行时间的30%* 10个CPU =每秒300 KB。 - 安全性:使另一个进程具有另一个进程的堆栈的值的含义可能是复杂的。 如果那里存在一些私钥或任何种类的个人身份信息(PII)怎么办?
虽然300 KB/s的数据量看起来并不多,但我们认为,对于运行CPU密集型应用程序的繁忙机器来说,这个数字可能会高得多。 我们希望通过在分析器运行时减少测量的影响,减少专用于分析器的资源,否则应用程序可能会使用这些资源。
另一个突然出现在我们脑海中的想法是复制BPF程序中的堆栈,但这仍然有我们希望避免的缺点,我们必须重新实现内核已经拥有的功能,而且它被证明工作得很好!
这就引出了我们最终采用的方法,仍然利用BPF!
Why BPF?
我们是 BPF 的忠实信徒,有很多原因。 从广义上讲,它允许 Linux 内核以更高的安全保证和更低的学习门槛进行编程。
在 BPF 中开发分析器非常有意义,因为一旦实现了堆栈遍历机制,我们就可以利用 perf 子系统来获取有关 CPU 周期、指令、L3 缓存未命中或我们机器中可用的任何其他性能计数器的样本。 它还有助于开发其他工具,如分配跟踪器、off-CPU分析器等。
你可能会想,为什么要在BPF中讨论堆栈展开? 使用bpf_get_stackid(ctx,& map,BPF_F_USER_STACK) helper,我们可以获取用户堆栈!事实上,这个助手使用帧指针遍历堆栈,而一个功能齐全的 DWARF 展开器不太可能登陆内核
展开表的BPF友好表示形式
大多数离线堆栈展开器不会处理大部分 DWARF CFI 信息,因为它们只针对很少的程序计数器。 另一方面,分析器可能会产生更高的程序计数器基数。 出于这个原因,事实上我们只需要数据的一个子集来遍历堆栈,因为我们不需要知道如何恢复每个寄存器,也不需要生成一些表示来最小化 BPF 的工作 unwinder 必须做,我们决定预先承担 unwind 表生成成本。
在用户空间中,我们首先解析、计算和生成回溯表。 到目前为止,我们只支持存储在.eh_frame ELF段中的信息。 生成的表是由以下行类型构建的几个数组:
typedef struct {
u64 pc;
u16 _reserved_do_not_use;
u8 cfa_type;
u8 rbp_type;
s16 cfa_offset;
s16 rbp_offset;
} stack_unwind_row_t;我们使用一个完整的字作为程序计数器,然后有几个字段帮助我们计算CFA。 例如,它可以与当前的$rsp或$rbp有一定的偏移量。 我们还将了解如何恢复$rbp。
使用上述算法,我们通过恢复前一帧的寄存器来遍历帧。 该表按程序计数器排序,以便能够在BPF程序中对该表进行二进制搜索。
当我们找不到给定PC的回溯信息,且当前的$rbp为零时,我们就完成了对堆栈的遍历。 然后,我们在内核空间的BPF map中聚合堆栈,以最大限度地提高效率,我们每分钟从用户空间收集两次数据,在用户空间生成配置文件并将其发送到Parca Server兼容的服务器。
开发
在我们开始这个项目的早期,我们就意识到有很多变量会影响它的成功。据我们所知,没有其他功能完整的、开源的、基于 DWARF 的 BPF 展开器,所以我们不确定它的可行性。 因此,为了最大限度地提高我们的成功机会,我们试图大幅减少问题空间,同时仍给我们尽可能多的信号。
在Polar Signals,我们为每一个我们想要讨论或获得反馈的大功能或主题创建了一个征求意见(RFC)。对于这项工作,我们从一个文档开始,列出了我们希望在第一次迭代中实现的目标,包括目标,更重要的是,非目标。
经过几个星期的工作,我们得到了第一个版本,它专注于正确性。 我们继续进行后续工作,以放宽最低内核要求(kernel ~4.10),并使展开表行更加紧凑。
在BPF中构建这是一个有趣的挑战。 内核必须确保任何加载的程序都不会使其崩溃,它使用BPF 验证器静态分析代码,验证器将拒绝或接受程序。 在写这篇文章的时候,一些当前的规则是,没有动态分配,终止必须是可证明的,以及许多其他的,所以我们必须有创造性地让验证器接受我们的程序。 这篇文章太长了,所以这将是另一个故事。
Testing测试
为了让展开器工作,展开表和 BPF 中实现的展开算法都必须运行良好。 确保table正确是该项目开发的重中之重。
在这种情况下,我们很早就决定以非常简单的形式使用快照测试。 我们在一个单独的git仓库中有一些测试二进制文件和预期的回溯表。 作为Agent中测试套件的一部分,我们重新生成表并确保没有任何更改。
这种技术允许我们快速迭代DWARF展开信息解析器,帮助我们找到大量的bug,并节省了大量的时间,否则我们将花费大量的时间来试图理解为什么我们在遍历堆栈时失败。
未来工作
我们正在修复、研发很多功能,将很快与您分享!
我们几天前才发布了第一个版本,其中包括基于DWARF的堆栈展开。 但是我们已经做了一些更多的改进,以确保分析器在内存受限的机器上运行良好,改进了体系结构,更好地支持JIT代码,等等。
近期,我们将重点转向可靠性、性能和更广泛的支持。 DWARF的回溯信息的解析、求值和处理尚未优化。 我们还希望确保我们的分析器具有详细的性能指标。 最后,我们希望对Clang和Rust编译器工具链生成的表进行更详尽的测试。
这个项目的最终目标是在默认情况下为我们的所有用户启用这个分析器,而不会导致明显更高的资源使用率。
试用
如上所述,这个新特性是在一个特性标志后面,但是我们将在下一个版本中默认启用它,一旦我们获得了一些改进,你可下载parca-agent当前的版本来体验。
$ ./parca-agent [...] --experimental-enable-dwarf-unwinding \
--debug-process-names="(postgres|mysql|redpanda)"与社区合作
我们认为,帧指针的普遍缺乏对于应用程序开发人员以及分析器、调试器和编译器的开发人员来说是一个大问题。
幸运的是,这个问题空间正在被更广泛的工程社区的许多成员积极地研究,比如在Fedora中默认启用帧指针的提议,或者the .ctf_frame work,这是一种DWARF展开的代替格式,专门为分析器和其他工具需要的在线、异步(意味着可以解旋任何程序计数器,而不仅仅是从特定部分)用例定制。
开源和与其他社区合作是我们公司精神的重要组成部分。 这就是为什么我们很早就开始谈论这个项目,从去年9月的 Linux Plumbers talk开始,在那里我们宣布了这项工作。
我们的unwinder是根据 GPL 许可证获得许可的。它开放供检查和贡献,我们很乐意与面临类似问题的其他项目合作。不要犹豫,伸出手!如果您希望在我们的Discord 或 GitHub discussion中看到任何反馈或功能,请告诉我们。
致谢
如果没有许多人的努力,这项工作是不可能完成的。 感谢如下项目。
- Go 的 Delve 调试器,我们的 DWARF 展开信息解析器基于它。
- Ian Lance Taylor 的 关于 .eh_frame 的博客系列。
- MaskRay 的博客 包含有趣的编译器和链接器内容。
- 参与 DWARF 标准和不同 ABI 的工程师。想出如此灵活的东西并不容易。开放和详细的规范是一个很好的资源。
- 编译器工程师是这项工作的无名英雄。创建展开表并不容易。在编译过程中保持它们同步是一项艰巨的任务。
- 如果没有 BPF 及其周围的生态系统,我们将无法安全地创建可编程的系统级分析器。虽然有时验证者可能很强硬,但它是我们最好的盟友。
- 可靠且快速的基于 DWARF 的堆栈展开论文 对我们在这篇文章中描述的所有系统提供了极好的描述,并尝试了一些不同的非 BPF 方法来加速基于 dwarf 的展开器,他们进行的一些正确性测试发现了几个错误。我们欠他们的不仅是提高许多系统(包括我们的系统)所依赖的展开表的质量,而且还帮助提高了对所有这些系统及其重要性的认识。
杂谈
- 虽然术语
stack walking堆栈遍历在分析器的上下文中更为正确,而stack unwinding堆栈展开通常在运行时处理异常时使用,但我们可以互换使用这两个术语。 - 我们的表格式使用了我们可以使用的最小数据类型,它对偏移量的最小值和最大值等设置了一些限制。您可以在本设计文档中查看它们,其中还包括一些
unwinder的要求。我们已经在努力消除上面提到的限制 Reliable and fast DWARF-based stack unwonding一文中的一个非常有趣的想法是,当展开表由于某种原因不存在或不完整时,从目标代码合成展开表。这是我们将来可能会考虑的事情。- 为了增加对复杂性影响的一些见解,仅就代码大小而言,之前基于帧指针的展开器可以在不到 50 行的 BPF 中重新实现,而这个基于 dwarf 的展开器超过 500 行。这排除了用户空间和测试中所有必要的支持代码。
- 最后但并非最不重要的一点是,不要把这项工作当作删除帧指针的道歉!如果我们可以改变计算行业中的一些技术和低级别的东西,它可能会默认启用帧指针。这是 Facebook 和谷歌等超大规模企业已经在做的事情,尽管可能会产生额外的计算成本,因为在故障排除的每一分钟都需要花费大量金钱的情况下,它们可以节省他们的头痛和时间。话虽如此,我们知道即使每个人都同意启用帧指针,也需要数年时间才能使我们的所有用户都获得好处。
旁注:C++ 异常机制非常复杂,必须完成本文中描述的大量工作。 一些有趣的事情需要考虑:展开表在内存中与不在内存中时的成本是多少? 这可能是您的应用程序的问题吗? 这些路径是如何行使的?
 CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:使用eBPF实现基于DWARF的堆栈遍历
CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:使用eBPF实现基于DWARF的堆栈遍历