译者注
我最近也在尝试用eBPF TC类型程序,挂钩egress网络包,修改IP包、TCP包内容,实现路由跟踪的功能。除了eBPF验证器的奇葩问题外,剩下的就是skb_buff修改后,被客户端内核丢弃、中间路由丢弃、服务端内核丢弃的各种问题,头发那是一把一把的掉。幸运的是,我找到了这篇文章Checksum-or-fxxk-up,写的特别好。看标题就知道作者被折腾不清,这点我感同身受。

TL;DR
如果你不想自讨苦吃,就千万别对checksum进行任何不当操作。但如果你想看到一个反面教材,继续阅读这篇由我这个不称职的人写的记录。
背景
我有一个挂钩在 ingress TC BPF程序,可以修改某些传入数据包的IP头部和TCP标志中的几个位。它在功能上表现得非常出色。直到…
dmesg 异常日志
在测试程序时,在dmesg中发现了以下消息:
[1216218.835883] <unknown>: hw csum failure
[1216218.843767] CPU: 11 PID: 3627719 Comm: ThriftIO15 Not tainted 4.16.18-210_fbk23_5358_gf2838c074351 #210
[1216218.862917] Hardware name: Quanta Twin Lakes MP/Twin Lakes Passive MP, BIOS F09_3A12 10/08/2018
[1216218.880669] Call Trace:
[1216218.885910] <IRQ>
[1216218.890287] dump_stack+0x46/0x68
[1216218.897272] __skb_checksum_complete+0xb0/0xc0
[1216218.906516] tcp_v6_do_rcv+0x12b/0x3d0
[1216218.914370] tcp_v6_rcv+0xad0/0xb00
[1216218.921701] ip6_input_finish+0xbf/0x460
[1216218.929903] ip6_input+0x80/0x90
[1216218.936714] ipv6_rcv+0x358/0x4c0
[1216218.943698] ? tcf_classify+0x87/0x120
[1216218.951551] __netif_receive_skb_core+0x541/0xa40
[1216218.961315] netif_receive_skb_internal+0x24/0xb0
[1216218.971080] napi_gro_receive+0xba/0xe0
[1216218.979105] mlx5e_handle_rx_cqe+0x83/0xd0
[1216218.987649] mlx5e_poll_rx_cq+0xc8/0x920
[1216218.995840] mlx5e_napi_poll+0xa1/0xc30
[1216219.003866] net_rx_action+0x128/0x340
[1216219.011718] __do_softirq+0xd4/0x2ad
[1216219.019219] irq_exit+0xa5/0xb0
[1216219.025850] do_IRQ+0x7d/0xc0
[1216219.032132] common_interrupt+0xf/0xf
[1216219.039798] </IRQ>我是如何陷入checksum深渊的。
根因与解决方案
这条消息显示出现了checksum错误。我让tcpdump重新检查,但他说checksum是正确的。然后我意识到入口TC BPF程序在tcpdump之后、内核接收数据包之前运行。这可以解释为什么tcpdump在checksum方面没有问题,而内核却报错。
根本原因很明确:入口BPF程序在TCP/IP头部篡改了位,但没有修复checksum。解决方案似乎也很简单:修复checksum就好了。
嗯,我将为我们节省一些时间,不再抱怨在一大堆与checksum相关的API中查找解决方案时的痛苦,比如bpf_l3_csum_replace、bpf_l4_csum_replace、bpf_csum_diff和bpf_csum_update。
更令人沮丧的是,最后一个简单的BPF_F_RECOMPUTE_CSUM标志传递给bpf_skb_store_bytes(用于修改位)就解决了问题。
checksum工作原理
在深入了解更多细节之前,让我们来看看checksum的工作原理。下面的图示非常好地阐述了这一点。(图片版权:Error Detection in Computer Networks)

为了避免混淆,在这篇文章中,我将使用术语“csum”来指代上图中的“sum”,并使用术语“checksum”来指代“csum”的1’s补码。正如你所看到的,只要数据没有被篡改,~(csum + checksum) == 0。
还有一个谜题
在调试过程中,我发现了一件有趣的事情 – 尽管错误被打印出来,但数据包并没有被丢弃,因此处理过程继续进行。为什么会这样呢?
由于上面的堆栈跟踪中没有显示某些内联函数,所以我将在这里“展开”调用堆栈的逻辑:
tcp_v6_do_rcv() {
// Checking checksum is unnecessary
if (skb_csum_unnecessary(skb)) {
nothing;
} else {
// Re-do checksum for whole skb
csum = skb_checksum(skb, 0, skb->len, 0);
// Check csum against skb->csum. If skb is intact, sum should be 0
sum = csum_fold(csum_add(skb->csum, csum));
if (sum == 0)
Print "hw csum failure" to dmesg and dump stack trace
else
Checksum fails, throw the skb away
}
// Continue processing skb
}当打印错误时,必须满足以下条件:
skb_csum_unnecessary返回false。- 如果我们计算
skb的checksum并将其与skb->csum进行比较,应该通过。也就是说,csum_add(skb->csum, skb_checksum(skb))应该返回零。
当skb_csum_unnecessary返回false时,意味着skb->csum_valid为false,这反过来又意味着在skb_checksum_init期间未将skb->csum_valid设置为1。这是因为原始的skb->csum和psum不相加得到零。还要注意,在skb_checksum_init之后,将skb->csum设置为psum。
说人话就是:
如果我正在运行,则表示检查硬件(NIC)提供的
skb-> csum与psm(稍后会讨论) 的一致性检查失败了。去你妈的硬件!(打印错误)但你知道吗?我重新计算了 skb 的checksum,并且它确实正确无误。让我们忘记硬件错误继续前进吧!
毫无疑问,硬件是清白的,罪魁祸首是我的 BPF 程序。所以即使数据包没有被丢弃,并且连接没有受到影响,我仍然修复了有罪的 BPF 程序来证明硬件的清白。
当我庆祝又一个结案时,我不知道罪犯正在干什么。

checksum又TM搞事情?
在部署BPF程序时,我发现一旦程序被attach,InCsumErrors就会不断增加。
$ netstat -s | grep InCsumErrors
InCsumErrors: 101继续调试
我不能谈论内核调试而不提到我的好朋友 – bpftrace。这一次,再次借助它的帮助,我能够将问题缩小到以下堆栈:
__skb_checksum_complete+1
tcp_v6_do_rcv+293
tcp_v6_rcv+2762
ip6_input_finish+186
ip6_input+128
ipv6_rcv+853
__netif_receive_skb_core+1312
netif_receive_skb_internal+36
napi_gro_receive+183
mlx5e_handle_rx_cqe+125
mlx5e_poll_rx_cq+194
mlx5e_napi_poll+161
net_rx_action+290
__softirqentry_text_start+207
irq_exit+165
do_IRQ+119
ret_from_intr+0
cpuidle_enter_state+176
do_idle+260
cpu_startup_entry+25
secondary_startup_64+165堆栈与之前的问题相同。然而,这次在dmesg中没有错误消息,并且数据包被丢弃,导致了重传。在tcpdump中,我看到的是以下序列:
- 一个TCP SYN数据包到达,但没有收到SYN-ACK。
- 一秒钟后,重新发送的SYN数据包到达并收到了SYN-ACK。
- 连接成功建立。
老天保佑
在浏览内核代码数小时后,我决定采用一种不太科学但有效的调试方法 – 尝试不同的事物,希望能找到一个可行的解决方案,并祈求上天提高成功率。
然后我注意到问题只发生在修改TCP头部时。即使使用BPF_F_RECOMPUTE_CSUM在修改后相应地修复了skb->csum。我决定看一下如果在修改TCP头部后不修复skb->csum会发生什么。而且,令人惊讶的是,它起作用了!
以下表格显示了我尝试过的事情及其结果:

至少有两个问题出现在这个表格中:
- 如果不重新计算IP头部更改的checksum,为什么会出现hw csum failure?
- 如果重新计算TCP头部更改的checksum,为什么会出现TcpInCsumErrors?
下一个目标是回答这两个问题,并确保我发现了解决方案而不是巧合。
寻找答案
TcpInCsumErrors错误发生是因为skb_checksum_init返回非零值。调用堆栈有点复杂。所以让我们再次简化逻辑(省略了无关的代码)。

这是我见过的最复杂的代码之一。
我在上述代码中标记了两个错误情况。我们需要非常小心地处理逻辑,以避免在处理checksum时出现这两个错误。
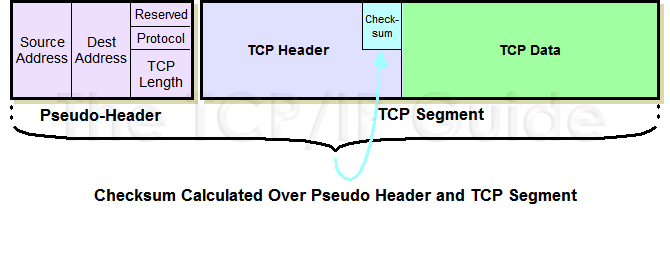
ip6_compute_pseudo 是什么?
它计算 TCP 伪头部的checksum。结果就是我们之前看到的 psum。(图片来源:[TCP Checksum Calculation and the TCP "Pseudo Header"](http://www.tcpipguide.com/free/t_TCPChecksumCalculationandtheTCPPseudoHeader-2.htm "TCP Checksum Calculation and the TCP "Pseudo Header""))
触发“hw csum failure”的条件如下:
~(psum + skb->csum) != 0,即检查skb->csum与psum的校验失败。~(skb_checksum(skb, 0, skb->len, 0) + psum) == 0,即对skb新计算的checksum与psum进行校验通过。
触发“TcpInCsumErrors”的条件如下:
~(psum + skb->csum) != 0,即检查skb的checksum与psum的校验失败。~((skb_checksum(skb, 0, skb->len, 0) + psum) != 0,即对skb新计算的checksum与psum进行校验也失败。
有些奇怪
你可能注意到了一些奇怪的地方。skb->csum与psum(伪头部的checksum)进行了比较。为什么会这样呢?难道不应该使用类似于~(skb->csum + checksum(skb)) == 0这样的方式,将其与整个skb的checksum进行比较吗?
我会尽力解释一下。关键在于,就像上面显示的图表所示,TCP头部也有一个checksum。

计算TCP头部checksum的公式是
tcp_hdr_checksum = ~(pseudo_hdr + tcp_hdr_with_checksum_0)注意:
- 我将使用“+”来表示“csum add”,这个算法将展示“checksum是如何工作的?”部分的图表中。
- payload被故意省略,因为它并不重要。
skb->csum 是由NIC使用整个数据包计算得出的16位checksum。即,
skb->csum = ip_hdr + tcp_hdr注意:
- 在进行csum add时,IP头和TCP头都会被切片,然后将它们的16位块相加/折叠在一起。
- 因为IP头、伪头部和TCP头都是16位对齐的,所以这两个公式可以重新写成
tcp_hdr_checksum = ~(pseudo_hdr_0_15 + pseudo_hdr_16_31 + ... +
tcp_hdr_0_15 + tcp_hdr_16_31 + ... + 0x0000 (checksum) + ...)如果我们在两边都进行~操作,我们得到
~tcp_hdr_checksum = pseudo_hdr_0_15 + pseudo_hdr_16_31 + ... +
tcp_hdr_0_15 + tcp_hdr_16_31 + ... + 0x0000 (checksum) + ...然后我们在两端添加tcp_hdr_checksum:
~tcp_hdr_checksum + tcp_hdr_checksum
= pseudo_hdr_0_15 + pseudo_hdr_16_31 + ... +
tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ...因为我们知道 ~tcp_hdr_checksum + tcp_hdr_checksum = 0xFFFF。所以
pseudo_hdr_0_15 + pseudo_hdr_16_31 + ... +
tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ... = 0xFFFF因此
tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ...
= 0xFFFF - (pseudo_hdr_0_15 + pseudo_hdr_16_31 + ... )
= 0xFFFF - psum我们可以将这个插入到skb->csum中。
skb->csum = ip_hdr_0_15 + ip_hdr_16_31 + ... +
tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ...
= ip_hdr_0_15 + ip_hdr_16_31 + ... + 0xFFFF - psum记住这个公式,我会回答上面的两个问题。
为什么在不重新计算IP头更改的情况下会出现“hw csum failure”?
(为简单起见,假设TCP头部未被修改。)
在内核网络堆栈中,在处理IP头部之后,它的checksum会从skb->csum中提取出来或者减去。然后skb->csum就变成了
skb->csum = (ip_hdr_0_15 + ip_hdr_16_31 + ... + 0xFFFF - psum) -
(ip_hdr_0_15 + ip_hdr_16_31 + ...)
= 0xFFFF - psum现在我们知道为什么在skb_checksum_init函数中,要将skb->csum与psum进行比较 – 因为它是公式中唯一剩下的变量。
然而,如果IP头部发生了改变(比如说,ip_hdr_16_31中的几个位被翻转),但是skb->csum没有相应地改变,那么它就会变成这样。
skb->csum = skb->csum - (ip_hdr_0_15 + ip_hdr_16_31 + ...)
= (ip_hdr_16_31 - ip_hdr_16_31) + 0xFFFF - psum第一个条件
~(psum + skb->csum) != 0或者(psum + skb->csum) != 0xFFFF。而数学计算如下:
psum + skb->csum = psum + (ip_hdr_16_31 - ip_hdr_16_31) + 0xFFFF - psum
= (ip_hdr_16_31 - ip_hdr_16_31) + 0xFFFF结果显然不是0xFFFF。因此第一个条件已满足。
第二个条件
~(skb_checksum(skb, 0, skb->len, 0) + psum) == 0或者skb_checksum(skb, 0, skb->len, 0) + psum == 0xFFFF。
skb_checksum(skb, 0, skb->len, 0) 是用于重新计算 skb 的checksum,此时 skb 只包含 TCP 头部。这将会
skb_checksum(skb, 0, skb->len, 0)
= tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ...
= 0xFFFF - psum因此
skb_checksum(skb, 0, skb->len, 0) + psum
= 0xFFFF - psum + psum
= 0xFFFF第二个条件也得到满足。问题已经得到回答。
为什么在重新计算TCP头部checksum时会出现“TcpInCsumErrors”?
(为简单起见,假设TCP头未被更改。)
请注意,当我们使用BPF_F_RECOMPUTE_CSUM时,它只会更新skb->csum而不会更新tcp_hdr_checksum。假设tcp_hdr_0_15中的几个位被翻转了。当调用skb_checksum_init时,实际上是在使用skb->csum。
skb->csum = tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ...
= tcp_hdr_0_15 - tcp_hdr_0_15 +
tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ...
= tcp_hdr_0_15 - tcp_hdr_0_15 + 0xFFFF - psum第一个条件
“TcpInCsumErrors”的判断条件为~(psum + skb->csum) != 0 或者 (psum + skb->csum) != 0xFFFF。所以数学计算如下:
psum + skb->csum = psum + tcp_hdr_0_15 - tcp_hdr_0_15 + 0xFFFF - psum
= tcp_hdr_0_15 - tcp_hdr_0_15 + 0xFFFF结果显然不是0xFFFF。因此第一个条件已满足。
第二个条件
“TcpInCsumErrors”的~(skb_checksum(skb, 0, skb->len, 0) + psum) != 0或者skb_checksum(skb, 0, skb->len, 0) + psum != 0xFFFF。
skb_checksum(skb, 0, skb->len, 0) 是重新计算 skb 的checksum。它将与 skb->csum 相同,因此数学上与第一个条件相同。换句话说,第二个条件也满足。
正如你所看到的,如果我们在更新tcp_hdr_0_15时不修复skb->csum,那么第一个条件将无法满足,代码将直接从快乐结局路径返回。
等一下,这不是一个黑客行为吗?
是的,我同意。更新TCP头部但不更新其checksum和skb->csum听起来像个黑客行为。另一种选择是:
- 更新TCP头部中的位。
- 更新
skb->csum以反映位变化。 - 更新TCP校验字段以反映位变化。
- 更新
skb->csum以反映TCP checksum的变化。
通过这种方式,TCP头部的差异和TCP checksum的差异相互抵消。数学计算如下:
skb->csum = tcp_hdr_0_15 + tcp_hdr_16_31 + ... + tcp_hdr_checksum + ...
= tcp_hdr_0_15 - tcp_hdr_0_15 +
tcp_hdr_0_15 + tcp_hdr_16_31 + ... +
tcp_hdr_checksum - tcp_hdr_checksum + tcp_hdr_checksum + ...
= (tcp_hdr_0_15 - tcp_hdr_0_15) +
(tcp_hdr_checksum - tcp_hdr_checksum) +
0xFFFF - psum
= 0xFFFF - psum既然结果与根本不触碰skb->csum相同,为什么不直接使用这个技巧呢?
要点
- 如果可以的话,请不要搞乱checksum。
- 发明checksum的人是一个天才。
- 我是个傻X。
 CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:eBPF挂钩TC egress时,被TCP Checksum搞死了
CFC4N的博客 由 CFC4N 创作,采用 署名—非商业性使用—相同方式共享 4.0 进行许可。基于https://www.cnxct.com上的作品创作。转载请注明转自:eBPF挂钩TC egress时,被TCP Checksum搞死了